There have been several major changes in the way we develop and deliver IT applications. We began with batch processing in the 1950s and progressed to time sharing, personal computers and now the Internet. With each new platform, application development has become easier.
To develop an application in the days of batch processing, you had to be a nerd -- a professional programmer. We used to keypunch assembly language programs then hand the card decks to operators who fed them to the computer in batches. It typically took a couple of hours to get your results back. Timesharing shortened the turnaround time, but professional programmers were still needed, and applications took months or years to build.
The personal computer enabled users to develop applications like newsletters, simple accounting systems, small databases and so forth using productivity software. Today one can develop a complex application like a blog, database, wiki or social network on the Internet with little effort.
But, what if you want to run your own applications on your own server? That is also getting easier and cheaper.
In the early days, you needed a computer to run the service and a connection to the Internet. It might have been a personal computer in your bedroom or on a shelf in a server room.
If the load grew, you could afford denser server blades in racks, but you were still responsible for maintenance and connectivity.
You could take care of the connectivity by moving your server into a data center, but it was still your server.
As personal computer power increased, we were able to borrow a page out of the mainframe book and partition a single physical server into several virtual servers. Then Amazon and others took it one step further -- taking care of scaling and connectivity by offering virtual servers in their data centers, but it still took a nerd to configure and manage them.
Today, companies like
Bitnami are raising the abstraction level and lowering the nerd bar, making it possible to deploy a server with installed applications in just a few minutes.
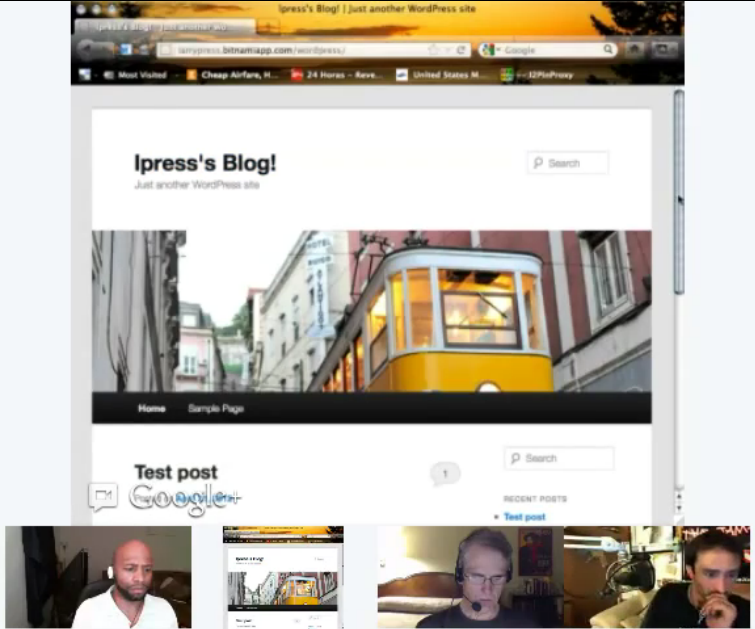
To demonstrate the ease of deploying applications, I created a virtual machine on the Amazon cloud and installed Web, wiki and blog servers. You can visit the server and check the three applications
here. Go there and you will see three fully operational applications.
I am not a system administrator or network engineer, but I was able to create the virtual server in the Amazon cloud and install and deploy the three applications in about ten minutes using Bitnami. (You can see the step-by-step installation
here).
Bitnami and others like it are raising the abstraction level. Soon we may be able to describe a virtual machine – its speed, memory and storage – and deploy it and its applications using a form like the one shown here.
In addition to specifying the server and its applications, this hypothetical form allows one to select cloud vendors. Today, Bitnami is tied to Amazon’s cloud, but one can easily imagine them offering a choice of cloud vendors.
If we were to dynamically allocate the resources needed to run an application -- changing them automatically when some performance thresholds was crossed -- one could just pick a vendor, select the applications to deploy and click
submit.
When that happens, your grandmother can be her own system administrator.