Bard made false, inconsistent statements, overlooked pertinent evidence, and overlooked expertise.
In an earlier post, I asked whether electronically steered antennas (ESAs) would replace parabolic antennas in satellite ground stations. I did some research and concluded that it is likely that they will. Next, I discussed the same question with ChatGPT and, while it made several false statements, it made a relevant point that I had overlooked. The relevant addition was positive, but the errors were troublesome, so I decided to try ChatGPT's competitor Google Bard.
Since the P in Chat GPT stands for "pre-trained," I began by asking Bard if it was more up-to-date than ChatGPT and it replied, "Bard is able to access the internet in real-time, while ChatGPT-4 is limited to a dataset that only goes up to late 2021." It added that it had last been updated on June 7, 2023.
That was encouraging since antenna technology has improved since late 2021 and at least two new products incorporating ESAs have been announced since that time, BlueHalo's mobile ground station and Thinkom's gateway array.
But my optimism faded when I began by asking Bard to "list the advantages of electronically steered antennas over parabolic antennas in ground stations for LEO Internet service constellations" and then asked it to "list the advantages of parabolic antennas over electronically steered antennas." The results of the two queries are shown here.
The replies are less complete and specific than those given by ChatGPT, and they are inconsistent -- Bard credits both ESAs and parabolic antennas as being cheaper. Furthermore, there was no indication that Bard was aware of the BlueHalo or Thinkom products, so I asked three leading questions:
- Have there been recent satellite ground station innovations?
- Any new hardware?
- Any innovative new products?
It did not mention either BlueHalo or Thinkom, but after the third try it suggested that I try a Google search for "Innovative new products for satellite ground station" and that returned many links, including one to the Thinkom array of antennas.
My next query demonstrated an extreme lack of awareness. I asked if China's Long March 5B rocket would be used to launch their
GuoWang satellite constellation. Bard
answered that it would and added that it "will be the first time that a country has launched such a large constellation of satellites."
Evidently, GuoWang is more frequently associated with Chinese propaganda than the SpaceX Starlink constellation in the Bard training set. (Garbage in, garbage out).
 |
Red and blue text indicates errors (source)
|
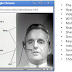
A final example illustrates Bard's inability to recognize expertise. I asked Bard "Who is Larry Press
", and it answered with the error-ridden professional biography shown here. The red text highlights statements that are false and the blue highlights work done in collaboration with others, not by me alone.
One can understand some of the errors. For example, I got my Ph.D. from UCLA, not USC, but I did teach at USC for a while and that may be more frequently mentioned in the training set. Similarly, I have been on several editorial boards, but I no longer am. I am an expert on my own biography and a simple Google Search would have found a somewhat dated, but accurate short biography on the Web.
I was also disappointed in the promise that Bard would provide links to references. It only cites references when it "
directly quotes at length from a webpage". I only saw one reference during my experimentation, and it was irrelevant.
"Artificial intelligence" programs have succeeded over the years in many specific tasks. As an undergraduate, I had the privilege of taking a course from Herbert Simon and learned about his chess-playing and theorem-proving programs. Arthur Samuel's
checker playing program learned to beat him, and expert systems assist doctors in making some diagnoses. I even wrote an interactive program based on
concept acquisition models that
assisted researchers in multivariate data analysis. (It could be an Internet service today).
Artificial neural nets have also had success in specific tasks from recognizing zip codes on envelopes to playing Go and Chess and helping robots do back flips and they will succeed at other tasks like
helping Microsoft Windows users or writing poetry. (I submitted
haikus written by Bard and ChatGPT to the AI detector
GPTZero and it
reported that they were "likely to have been written entirely by a human"). But none of these programs are generally intelligent.
The illusion of intelligence results from the ability to generate responsive grammatical sentences in a conversation, but that is a low bar. Many years ago, I placed Teletype terminals in a public library and people conversed, sometimes for hours, with ELIZA, a simple simulation of a non-directive therapist. You can try ELIZA for yourself here. The common practice of referring to errors as "hallucinations" furthers the illusion of intelligence.
Update 9/27/2023
I could not recall the verb "scrub" for navigating through a timeline, so I asked ChatGPT and Bard for help.
ChatGPT got it;
Update 10/25/2023
A colleague told me that Bard had cited him as the author of a journal article. I searched for it using Google and could not find it so I asked him about it. It turned out that he had never written an article with the cited title and that the journal it cited had gone out of print two years before the cited publication date.